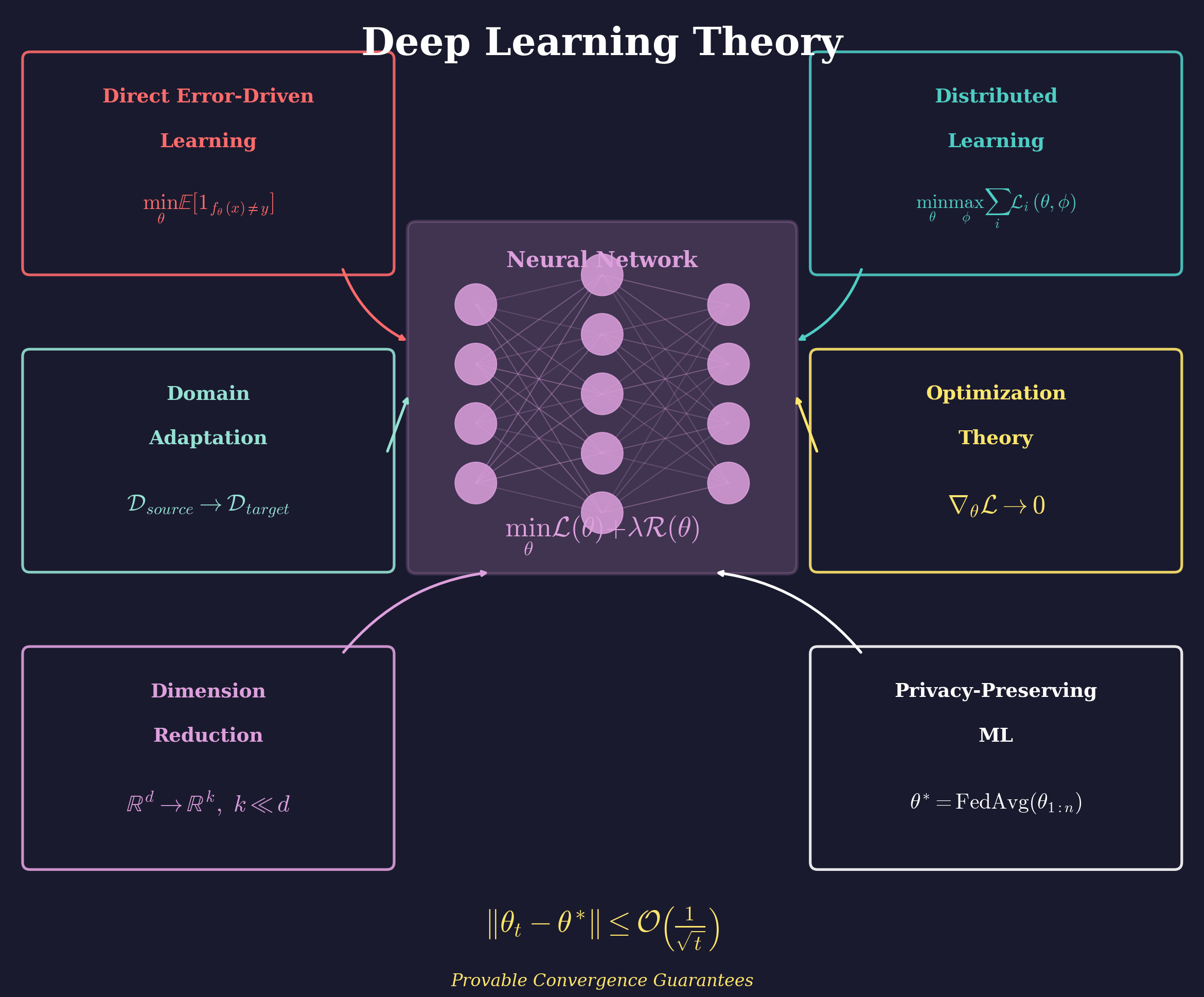
My research in deep learning foundations develops training algorithms with provable convergence guarantees, distributed learning methods for large-scale systems, and techniques for handling challenging data scenarios.
Direct Error-Driven Learning: Novel training algorithms that directly minimize classification error rather than surrogate losses, providing theoretical guarantees for deep network training on high-dimensional data. This work bridges optimization theory with practical deep learning.
Distributed Learning: Game-theoretic and min-max optimization frameworks for training neural networks across distributed computing environments, with applications to big data classification problems where data cannot be centralized.
Domain Adaptation: Addressing distribution shift between training and deployment through adversarial and game-theoretic approaches that learn domain-invariant representations, critical for deploying ML models in evolving real-world environments.
Dimension Reduction: Hierarchical and multi-step nonlinear methods for reducing dimensionality of big data while preserving discriminative information for downstream classification and regression tasks.
Privacy-Preserving ML: Federated learning approaches for scientific applications where data cannot be centralized due to privacy, security, or governance constraints across institutions and national laboratories.
Multi-Agent Systems: Credit assignment methods for multi-LLM agent systems, addressing the challenge of attributing rewards and blame when multiple AI agents collaborate on complex tasks.
Publications
- Cooperative Deep Q-Learning Framework for Environments Providing Image Feedback - IEEE TNNLS 2024
- A Game Theoretic Approach for Addressing Domain-Shift in Big-Data - IEEE Transactions on Big Data 2022
- Distributed Min-Max Learning Scheme for Neural Networks with Applications to High-Dimensional Classification - IEEE TNNLS 2021
- Direct Error-Driven Learning for Deep Neural Networks with Applications to Big Data - IEEE TNNLS 2020
- A Multi-Step Nonlinear Dimension-Reduction Approach with Applications to Big Data - IEEE TKDE 2019
- A Hierarchical Dimension Reduction Approach for Big Data with Application to Fault Diagnostics - Big Data Research 2019
- Privacy-Preserving Federated Learning for Science: Challenges and Research Directions - IEEE BigData 2024
- Who Gets the Reward, Who Gets the Blame? Evaluation-Aligned Training Signals for Multi-LLM Agents - arXiv 2025